This article explains synthetic data in plain language - what it is, why we need it, and how to use it. Through vivid metaphors and everyday examples, readers can easily understand this seemingly complex technical concept. Whether you're a technical expert or a beginner, you'll find valuable insights in this guide.
Jessy Tsui
October 22, 2024
We will be publishing articles about synthetic data and data engineering, including both educational content and analytical perspectives. This piece aims to break down the reasons behind the surge in synthetic data's popularity while explaining this field in simple terms. More in-depth analysis will follow in future updates.

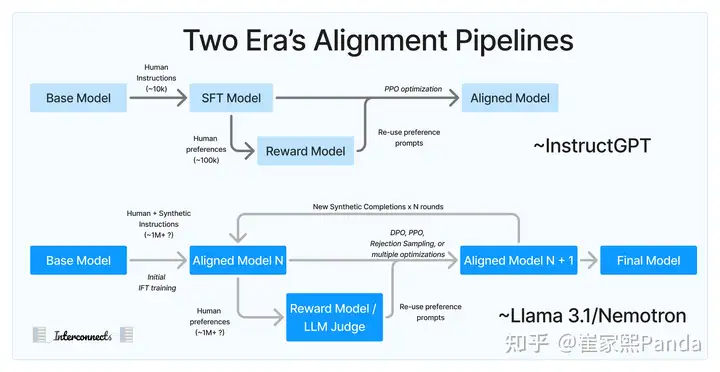
Many researchers are trying to find the "optimal ratio between SFT and RLHF," but most can only reference somewhat outdated works like InstructGPT, WebGPT, Sparrow, and papers about Helpful and Harmless Assistant.
Before Llama 3.1, teams with LLM training experience followed the rule of thumb: "10k high-quality instructions and 100k preference data."
While these pioneering works contributed significantly to the initial development of ChatGPT and helped the research community catch up with OpenAI, they are now outdated and don't align with current RLHF training methods.
Although the fundamental evaluation criteria and training objectives might remain similar, the details have undergone revolutionary changes.
The Llama 3.1 paper includes extensive details about its post-training process. Subsequently, model reports from Nvidia's Nemotron 340B, Apple Intelligence, and Gemma 2 clearly indicate a new, more advanced approach to RLHF training. This approach relies on several experimental hypotheses:
Two Nature papers widely reported in July claimed that excessive use of synthetic data leads to model collapse.
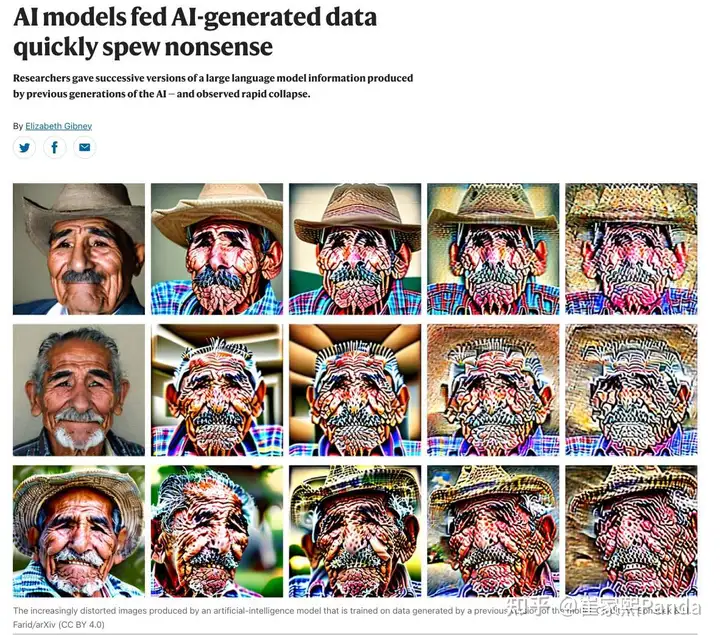

Researchers deliberately conducted experiments under conditions that don't match real-world scenarios
How should we understand this?
The model collapse issue stems from the question: "What happens when using synthetic data generated by previous models to pre-train new generative models?"
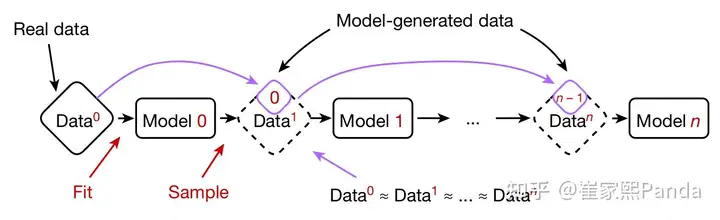
The Nature paper's experimental conditions were set up with:
Both conditions don't reflect real-world scenarios.
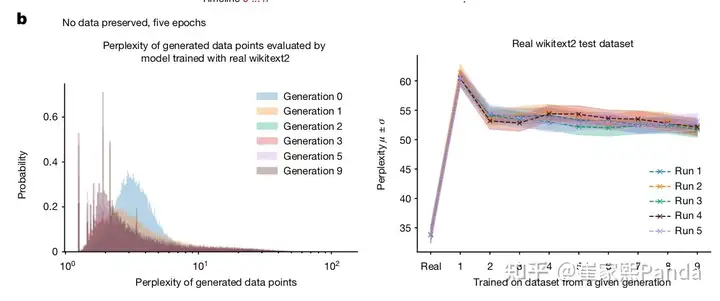
They also conducted a comparative experiment that didn't match real situations: Maintaining a constant dataset size while keeping 10% of the original data but replacing the other 90%.
Note: Despite this, they observed lower perplexity by adding some real data.
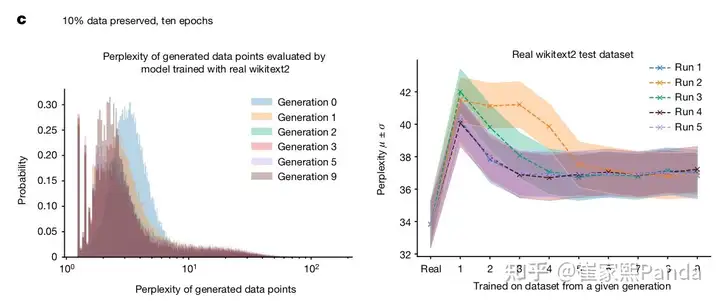
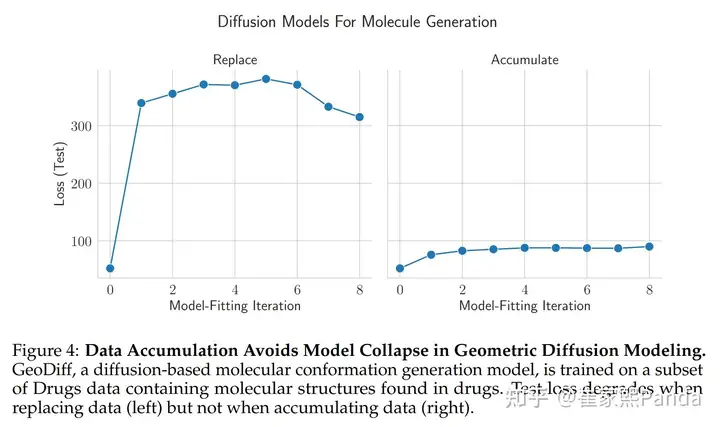
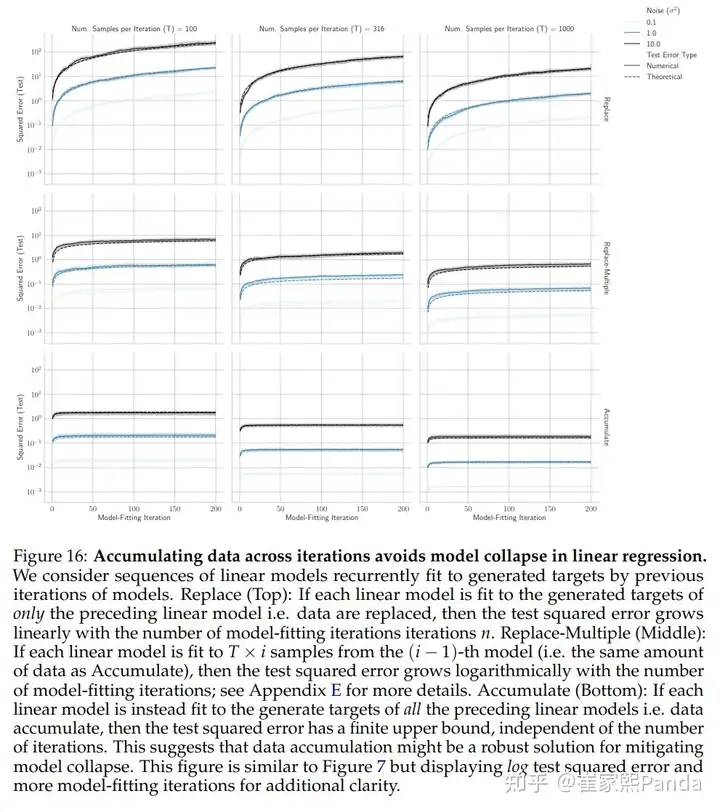
What happens if we retain all data and only add new data? We can look at the COLM paper for answers:
If we do this, meaning data accumulates (right figure), the model doesn't collapse ✅ If we don't do this, meaning data gets replaced (left figure), the model collapses ❌
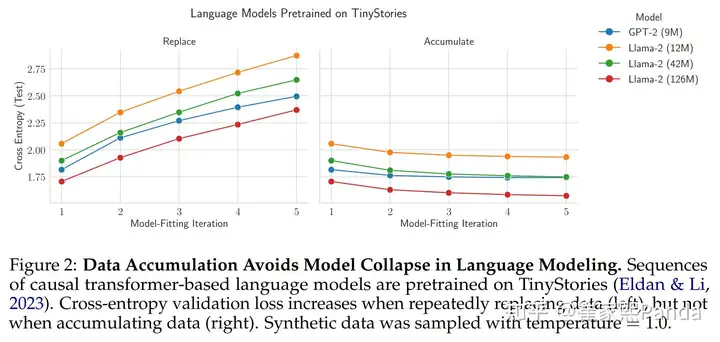
These results have been proven across various domains (text, vision, molecules) and models (transformer, VAE, diffusion).
In today's rapidly developing AI landscape, the saying "data is AI's food" hits the mark. Just as humans need nutritionally balanced food to maintain health, AI systems need high-quality, rich data to improve performance. However, quality data, like ingredients from a three-Michelin-star restaurant, is often difficult to obtain and costly. In this context, "synthetic data" acts like a nutrition formulator who can perfectly replicate fine cuisine, providing AI with an inexhaustible "nutritional source."
Imagine you're opening a restaurant. You need:
Here, synthetic data acts like a magical nutrition formulator who can:
Copy
Example: Movie Review Generation Requirements
- Quantity: 1000 reviews
- Distribution: 500 positive, 500 negative
- Length: 50-100 characters each
- Elements: Include emotion, plot, acting evaluation
Copy
Task: Generate movie review
Movie: "Inception"
Requirements:
- Evaluation must be well-reasoned
- Must mention plot and special effects
- Include personal viewing experience
Copy
Generated Result:
"'Inception' is a dual feast for both visuals and mind.
Nolan's narrative approach is fascinating, with layered
dream structures that immerse viewers. The special effects
are excellent, especially that iconic city-folding scene,
which remains unforgettable."
Copy
Patient Case:
Name: Zhang** (anonymized)
Age: 65
Chief Complaint: Persistent headache, mild dizziness
Examination Results:
- Blood Pressure: 145/90 mmHg
- Heart Rate: 78 bpm
- Blood Sugar: 6.2 mmol/L
Family History: Father had hypertension
Copy
Transaction Record:
Time: 2024-01-15 03:21:15
Amount: ¥8,888.00
Location: Remote (1500km from usual location)
Features:
- Unusual time period
- Multiple large transactions in succession
- Abnormal geographic location
Copy
Customer Feedback:
"Hello, I bought a phone yesterday and found it makes strange
noises after turning it on today. The battery only lasts 3
hours, which clearly doesn't match the product description.
I hope this issue can be resolved quickly."
Customer Service Reply:
"Hello, I sincerely apologize for the inconvenience. Could
you please provide your order number and device model? We
will prioritize your issue and arrange for professional
technicians to conduct testing and repairs."
Just as chefs use different cooking methods to create various flavors from one dish, data augmentation is a technique that creates multiple variants from one piece of data.
Data augmentation generates more diverse data through various transformation methods. For example:
Copy
1. Synonym Replacement
Original: "This phone's battery is durable"
Variant: "This phone's battery life is excellent"
2. Sentence Restructuring
Original: "The phone is beautiful and performs well"
Variant: "Not only does it perform excellently, but it also looks outstanding"
3. Content Expansion
Original: "This movie is touching"
Variant: "This movie has a touching plot, especially the father-son reunion scene at the end that brings tears to one's eyes"
Like doctors monitoring patient indicators, data monitoring performs real-time "health checks" on generated data.
Copy
Key Monitoring Indicators:
1. Data Completeness
- Whether key information is missing
- Whether format is standardized
2. Data Accuracy
- Whether facts are correct
- Whether logic is reasonable
3. Data Diversity
- Whether content is monotonous
- Whether expressions are repetitive
Copy
Monitoring Approaches:
✅ Automated Checks
- Format validation
- Rule matching
- Statistical analysis
🔍 Manual Sampling
- Quality assessment
- Content review
- Professional verification
Like food safety testing, ensuring generated data meets usage standards.
Copy
Dimension | Description | Check Method
Accuracy | Content accuracy | Fact verification
Completeness | Information completeness | Field checking
Consistency | Logic uniformity | Rule validation
Timeliness | Information currency | Time checking
Copy
1. Preventive Control
- Set generation rules
- Establish quality standards
- Optimize generation templates
2. Process Control
- Real-time monitoring
- Timely correction
- Dynamic adjustment
3. Result Control
- Sample inspection
- Quality assessment
- Feedback optimization
Like preparing a complex dish requires multiple steps, complex data also needs step-by-step generation.
Copy
Step One: Framework Generation
🏗️ Determine main structure
Example: Question-answer basic framework
Step Two: Content Filling
📝 Add specific content
Example: Detailed question description and answer steps
Step Three: Detail Optimization
✨ Add details and polish
Example: Add technical terms, adjust language style
Step Four: Quality Enhancement
🔍 Optimize and perfect
Example: Check logic, add examples
Copy
Generating Customer Service Dialogue:
1️⃣ Framework Determination:
Customer: [Problem description]
Service: [Initial response]
Customer: [Follow-up question]
Service: [Solution]
2️⃣ Content Filling:
Customer: "My phone suddenly won't turn on"
Service: "Hello, what model is your phone?"
Customer: "iPhone 13"
Service: "Okay, let's try some basic troubleshooting"
3️⃣ Detail Addition:
Customer: "My iPhone 13 suddenly went black and won't turn on, there were no previous issues"
Service: "Hello, I'm sorry for the trouble. Has the phone been exposed to water or dropped?"
Customer: "No, I've always been very careful with it"
Service: "Okay, let's try a force restart: Press and hold both the volume up and power buttons for 10 seconds..."
4️⃣ Optimization and Refinement:
[Add more technical details]
[Add possible cause analysis]
[Include success rate information for solutions]
Like a factory production line, connecting various processing stages in order.
Copy
A[Requirements Analysis] --> B[Data Design]
B --> C[Initial Generation]
C --> D[Quality Testing]
D --> E[Data Augmentation]
E --> F[Final Acceptance]
Copy
1. Input Layer
- Requirement confirmation
- Parameter setting
- Template preparation
2. Processing Layer
- Data generation
- Quality control
- Format conversion
3. Output Layer
- Result verification
- Data storage
- Usage distribution
These concepts form the foundation for building high-quality synthetic data. Understanding them helps us better apply synthetic data technology. Just as creating fine cuisine requires mastering various cooking techniques, generating good synthetic data requires proficient use of these technical tools.